Ce billet de blog appartient à une série destinée à raconter mes aventures dans le monde de la fouille de données et de l’analyse textuelle automatique. Mon objectif (personnel) est d’explorer par la pratique les difficultés épistémologiques et méthodologiques rencontrées dans ce type d’exercice. Mais aussi de parvenir à déterminer des cas dans lesquels de tels outils sont bel et bien utiles.
Le terrain choisi pour cette expérience est l’analyse des courriels diffusés sur la liste de diffusion publique du groupe d’intérêt sur la vie privée du W3C (Privacy Internet Group – PING).
Dans le précédent billet de cette série, j’avais évoqué l’évolution de l’utilisation d’un terme dans la mailing-list au fur et à mesure des mois. Mais quels mots évoluent en même temps ?
Pour le savoir, il faut calculer le coefficient de corrélation (le R de Pearson) entre paires de vecteurs comprenant pour chaque mois le nombre de fois ou le mot a été utilisé (ou bien sa fréquence).
La librairie Scipy contient une fonction pearsonr() qui permet de le calculer de façon pratique :

Cette fonction prend comme argument des listes de valeur, et retourne deux données : le R de Pearson et la « valeur p » qui est un indicateur de la fiabilité de la corrélation. Pour l’instant, seul le R de Pearson, c’est-à-dire l’indicateur de corrélation nous intéresse. Celui-ci est égal à 1 en cas de corrélation parfaite, et égal à – 1 en cas de parfaite corrélation inverse.
Grâce à Python, nous pouvons tester toutes les combinaisons possibles entre mots utilisés dans la mailing-list.
[Difficulté] Faire cela prend un temps remarquablement fou.
Demander à l’ordinateur de calculer tous les coefficients de corrélation pour 34 mots en entrée sur une période de 75 mois génère 561 paires de mots entre lesquels le coefficient est calculé, ce qui ne prend qu’un tout petit plus d’une seconde. Mais faire la même chose pour les plus de 22 000 mots utilisés dans la liste de diffusion depuis sa création … prend de nombreuses heures (j’ai éteint mon ordinateur au bout de 6 heures, il n’avait pas encore terminé)
Ceci permet de générer un fichier CSV qui indique le coefficient de corrélation pour chaque paire de mots testée, qu’il est alors possible de trier dans Calc par ordre croissant ou décroissant :
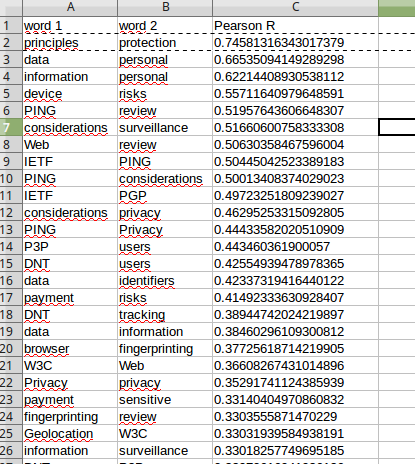
[Utile] Ceci permet de révéler que certains mots sont probablement souvent utilisés ensemble. En effet, “personal” et “data” sont souvent utilisés pour dire “personal data”. Ici, l’exemple est évident, et il conviendrait de considérer en réalité “personal data” comme un terme à part (et distinct de “personal” et de “data” employés tous seuls). Cependant, d’autres combinaisons moins évidentes peuvent être détectées (par exemple : “payment” et “risk”, “payment” et “sensitive”, “browser” et “fingerprinting”). Ce n’est pas anodin qu’il y ait une telle corrélation entre payment”, “sensitive” et “risk” … Cela montre que le paiement est considéré comme un domaine particulièrement risqué.
Ceci permet des courbes, mais elles ne sont pas forcément bien belles :
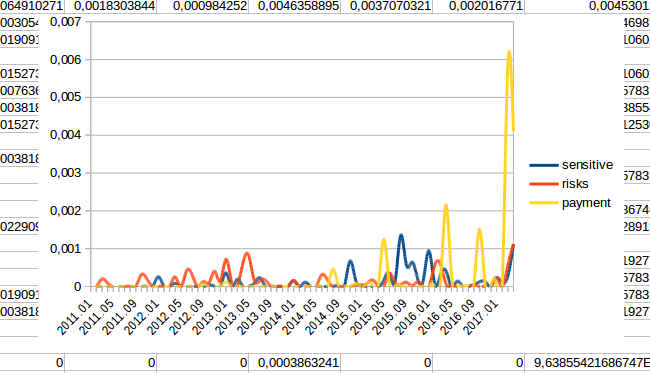
Pourtant, selon le coefficient calculé, les courbes devraient bien plus se suivre ! Et pourtant aussi, cela fait sens que les trois mots soient employés ensemble.
En y regardant de plus près, un des seuls pics communs d’utilisation de ces trois termes est en janvier 2013. Par curiosité, on peut aller voir dans quel contexte on les retrouve ensemble … Cela serait beau de les voir employés ensemble. Mais, dans la réalité, le mot “payment” n’est utilisé en janvier 2013… qu’une seule fois ! Et dans un contexte où il n’est associé ni à la notion de risque, ni à celle de paiement :
« For example if users happen to want to donate to Google or Yahoo or Facebook for the great service they provide then these website authors could include a payment destination for the users chosen advertising network donation. If users want to channel their rewards back to Mega movie viewing rewards then they also have this choice. Obviously this would all need to be a private matter between the user and their chosen advertising network and this may require some enhanced web browser security and perhaps the work of the PUA CG could help but this could depend on how its implemented. »
— https://lists.w3.org/Archives/Public/public-privacy/2013JanMar/0014.html
En réalité, nous ne trouvons que bien peu de trace d’emploi combiné des mots “payment”, “risk” et “sensitive”. C’eut pourtant été beau de pouvoir l’affirmer statistiques et grosse donnée à l’appui ! Mais tout à fait malhonnête. Est-ce à dire que les trois termes ne seraient absolument pas reliés dans l’imaginaire des gens qui participent au W3C PING ? Nous ne pouvons pas non plus y conclure par manque d’informations sur le sujet. Nous avons tout simplement trop peu d’occurences du mot “payment” pour conclure quoi que ce soit de cette analyse quantitative et nous devrions, si la question nous intéressait, procéder par des méthodes qualitatives.
[Limite] Dans un certain nombre de cas, une analyse qualitative peut se révéler bien plus précise et utile qu’une analyse quantitative, et ce, même si a priori le corpus de données paraît important.
Par ailleurs, la méthode d’analyse par corrélation est, pour découvrir le contexte d’utilisation d’un mot, bien moins intéressante que la méthode par analyse de distance entre deux mots dans un texte (l’analyse de proximité textuelle), qui peut être alors représentée sous forme d’arbre de proximité (nous nous pencherons dessus à un autre moment).
Quoi qu’il en soit, en explorant les corrélations entre l’évolution de l’emploi de différents mots, nous voyons tout de même parfois apparaître de belles courbes. Par exemple, entre les termes “PING”, “PGP” et “IETF”. Est-ce à dire que l’IETF et PING ont discuté ensemble du chiffrement par clef PGP ?
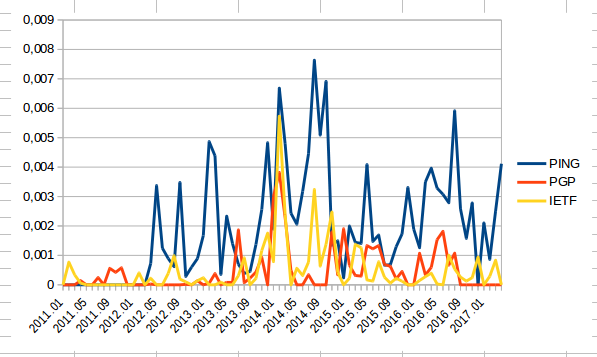
En février 2014, nous voyons une nette corrélation entre l’emploi de ces trois mots !
[Difficulté] Pourtant, une fois n’est pas coutume : une corrélation statistique ne signifie pas nécessairement qu’il existe une cause pouvant l’expliquer, et elle peut donc tout à fait ne rien vouloir dire du tout. Il faut donc toujours aller vérifier si elle veut dire quelque chose, et si oui, ce qu’elle veut dire, l’interprétation ne découlant pas automatiquement de la lecture statistique des données.
Ici, je suis donc aller voir ce qui, en février 2014, expliquerait une telle corrélation entre les trois termes. En lisant les titres des mails de la période, on voit apparaître en effet des discussions sur une réunion commune W3C PING – IETF :

[UTILE] Pour une fois, le fait d’avoir découvert un beau pic de corrélation entre deux termes (PING et IETF) a effectivement permis de découvrir une cause : l’organisation en 2014 d’une réunion W3C PING – IETF. L’existence de cette réunion, dont l’existence contribue à montrer l’existence de discussions entre le W3C et l’IETF pour définir une approche commune quant à la protection de la vie privée dans les standards techniques du web, a pu être décelée bien plus rapidement qu’en parcourant à la main tous les titres de mails (voire leur contenu) depuis le début de l’existence de la liste de diffusion.
Hélas, il s’est cependant révélé que la corrélation entre “PGP” et le couple “PING”/”IETF” n’avait rien à voir avec le thème des discussions entre le W3C PING et l’IETF.
En effet, en lisant les mails de la période, on ne tombe que sur un seul mail qui parle du contenu de cette réunion entre W3C PING et IETF. Il s’agit d’un morceau du compte-rendu d’une autre réunion, ayant eu lieu dans les locaux de l’ONG Center for Democracy and Technology (CDT), où un participant a évoqué la réunion PING – IETF qui venait d’avoir lieu.
Or, la discussion n’a pas du tout porté sur le chiffrement PGP, mais sur des questions de méthode de travail et sur le projet de recommandation de l’IETF en matière de vie privée (qui a donné la RFC 6973).
D’où vient donc ce pic d’utilisation du terme “PGP” ?
Tout simplement du fait qu’un des participants à la mailing-list du W3C PING inclut dans ses mails sa signature PGP, et qu’il a joué un rôle important dans la réunion entre le W3C PING et l’IETF. Il a donc envoyé un nombre important de
messages sur la période, pour effectivement parler d’un sujet mêlant “PING” et “IETF”, mais pas “PGP”.
Donc cette triple corrélation PING – IETF – PGP ne nous dit rien sur le thème des discussions entre le W3C PING et l’IETF, mais juste sur une des personnes impliquées dans ces discussions, dont nous apprenons qu’elle inclut sa clef publique PGP dans ses mails …
[Difficulté] Ainsi, non seulement il serait vain de trouver une cause à toute corrélation, mais en plus, même lorsqu’une corrélation est dotée d’une cause, celle-ci peut être compliquée à trouver, et même impossible à trouver par de simples méthodes statistiques. Or, vérifier par des méthodes qualitatives chaque corrélation statistique peut prendre beaucoup, beaucoup de temps …
Ping : Attention au temps ! – Blog